
Raven llm
내 컴퓨터 안의 ChatGPT, Raven
뭔가 엄청난 걸 본 것 같다. Raven - RNN 기반 LLM의 역습 (Alpaca와 비슷한 퀄리티, 빠른 동작 이다. ChatGPT를 내 로컬 컴퓨터에 심을 수 있는 뭐 그런 건가보다.
궁금해서 당장 동영상의 내용대로 따라해봤다.
데모 테스트
허깅페이스는 모델만 올릴 수 있는 게 아니라 모델을 돌려볼 수 있는 공간도 제공한다. 허깅페이스 스페이스 라는 곳인데, 유료로 사용하거나 또는 커뮤니티 지원(좋아요 같은 개념인 것 같다)을 받으면 무료로 고성능 컴퓨팅 자원(GPU)을 사용할 수 있다.
https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B
이게 데모 페이지이다. ChatGPT를 생각하고 돌려보면, 뭔가 아쉽다. 예를 들어 “Make me a 99 bottles of beer for python” 이라고 하면 코드를 만들다가 마는 것을 볼 수 있다. 토큰 제한 때문인데, 로컬에서 돌린다면 이 제한을 풀 수 있을 거라는 생각이 들었다.
다운로드 및 설치
데모 앱 다운로드
데모 페이지에 접속한다.
오른쪽 구석의 ... 를 클릭해 Clone repository를 클릭한다.
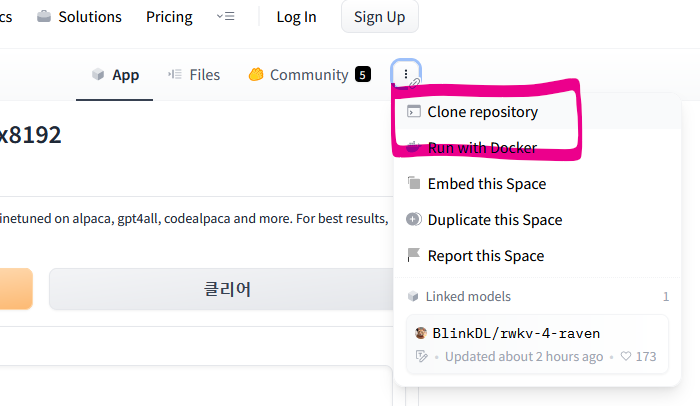
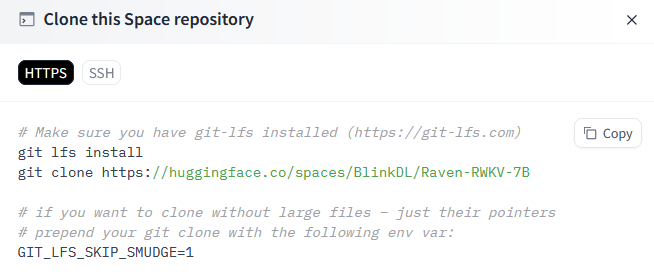
데모 페이지 자체에는 모델 파일이 없으므로 git lfs는 필요없다.
git clone https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B
실행 환경 설정
참고로 파이썬 버전은 3.10.6이다. python 3.11 버전은 아마 오류가 날 것이다. 아직 머신러닝 패키지들이 최신 버전 파이썬에서는 문제가 생긴다. 그나마 3.8에서 3.10으로 업그레이드가 되었으니 다행이다.
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
이 작업은 한번만 하면 된다. 다음에 다시 Raven을 실행시키려고 할 때는
source venv/bin/activate
만 실행하면 된다. 프롬프트 앞에 (venv) 가 표시되는 걸 확인하자.
모델 다운로드
내 그래픽카드로는 VRAM이 초과돼서 그대로는 돌릴 수가 없다. 다른 모델을 찾아봐야 한다.
https://huggingface.co/BlinkDL/rwkv-4-raven 에 접속한다.
Files and versions 를 클릭한다.
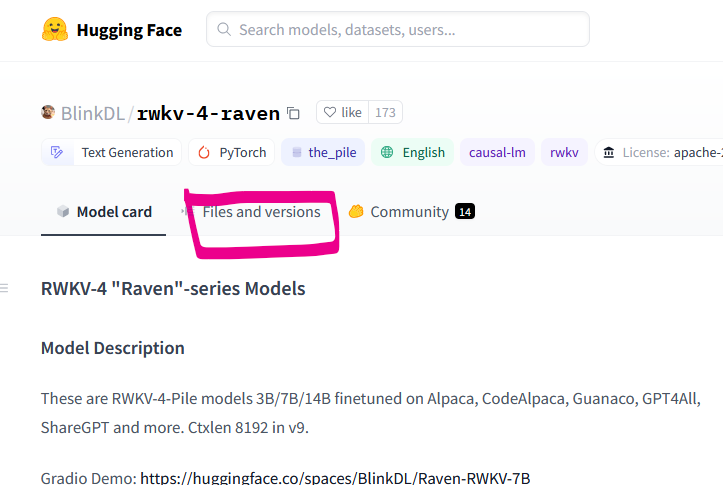
목록 중에서 파일 용량이 본인 GPU VRAM보다 작은(아마도) 모델 파일을 다운로드받는다.
다운로드받은 파일을 위에서 클론한 리포지토리의 /models 폴더에 복사한다. 폴더가 없을 텐데 새로 만든다.
파라미터 수정
title 을 다운받은 모델 이름으로 변경한다.
title = "RWKV-4-Raven-3B-v9-Eng99%-Other1%-20230411-ctx4096"
model_path 를 수정한다.
model_path = f"models/{title}.pth"
기존에는 이렇게 되어 있었을 것이다.
model_path = hf_hub_download(repo_id="BlinkDL/rwkv-4-raven", filename=f"{title}.pth")
hf_hub_download는 유틸리티 함수로, 허깅페이스에서 모델을 자동으로 다운로드해주는 도구이다. 원하면 파일을 직접 다운로드하는 대신 이걸 사용해도 된다.
strategy는 어쩌면 수정해야 할 지도 모른다. 본인 VRAM이 작아서(작업 관리자로 확인해보자. Ctrl+Shift+ESC 누르면 나온다) 실행이 안 되면 https://pypi.org/project/rwkv/ 에 적힌 설명에 따라 strategy를 수정한다.
########################################################################################################
#
# Use '/' in model path, instead of '\'. Use ctx4096 models if you need long ctx.
#
# fp16 = good for GPU (!!! DOES NOT support CPU !!!)
# fp32 = good for CPU
# bf16 = worse accuracy, supports CPU
# xxxi8 (example: fp16i8, fp32i8) = xxx with int8 quantization to save 50% VRAM/RAM, slower, slightly less accuracy
#
# We consider [ln_out+head] to be an extra layer, so L12-D768 (169M) has "13" layers, L24-D2048 (1.5B) has "25" layers, etc.
# Strategy Examples: (device = cpu/cuda/cuda:0/cuda:1/...)
# 'cpu fp32' = all layers cpu fp32
# 'cuda fp16' = all layers cuda fp16
# 'cuda fp16i8' = all layers cuda fp16 with int8 quantization
# 'cuda fp16i8 *10 -> cpu fp32' = first 10 layers cuda fp16i8, then cpu fp32 (increase 10 for better speed)
# 'cuda:0 fp16 *10 -> cuda:1 fp16 *8 -> cpu fp32' = first 10 layers cuda:0 fp16, then 8 layers cuda:1 fp16, then cpu fp32
#
# Basic Strategy Guide: (fp16i8 works for any GPU)
# 100% VRAM = 'cuda fp16' # all layers cuda fp16
# 98% VRAM = 'cuda fp16i8 *1 -> cuda fp16' # first 1 layer cuda fp16i8, then cuda fp16
# 96% VRAM = 'cuda fp16i8 *2 -> cuda fp16' # first 2 layers cuda fp16i8, then cuda fp16
# 94% VRAM = 'cuda fp16i8 *3 -> cuda fp16' # first 3 layers cuda fp16i8, then cuda fp16
# ...
# 50% VRAM = 'cuda fp16i8' # all layers cuda fp16i8
# 48% VRAM = 'cuda fp16i8 -> cpu fp32 *1' # most layers cuda fp16i8, last 1 layer cpu fp32
# 46% VRAM = 'cuda fp16i8 -> cpu fp32 *2' # most layers cuda fp16i8, last 2 layers cpu fp32
# 44% VRAM = 'cuda fp16i8 -> cpu fp32 *3' # most layers cuda fp16i8, last 3 layers cpu fp32
# ...
# 0% VRAM = 'cpu fp32' # all layers cpu fp32
#
# Use '+' for STREAM mode, which can save VRAM too, and it is sometimes faster
# 'cuda fp16i8 *10+' = first 10 layers cuda fp16i8, then fp16i8 stream the rest to it (increase 10 for better speed)
#
# Extreme STREAM: 3G VRAM is enough to run RWKV 14B (slow. will be faster in future)
# 'cuda fp16i8 *0+ -> cpu fp32 *1' = stream all layers cuda fp16i8, last 1 layer [ln_out+head] cpu fp32
#
# ########################################################################################################
마지막으로 우리는 데모보다 더 많은 토큰 수를 원하므로, token 수를 2000 개로 조정한다. 아래 세 부분을 바꾸면 된다.
def evaluate(
instruction,
input=None,
##############################
token_count=2000, # 200 → 2000
##############################
temperature=1.0,
top_p=0.7,
presencePenalty = 0.1,
countPenalty = 0.1,
):
with gr.Column():
instruction = gr.Textbox(lines=2, label="Instruction", value="Tell me about ravens.")
input = gr.Textbox(lines=2, label="Input", placeholder="none")
###########################################
# Edit this below. 200 -> 2000, value=150 -> 2000
token_count = gr.Slider(10, 2000, label="Max Tokens", step=10, value=2000)
###########################################
temperature = gr.Slider(0.2, 2.0, label="Temperature", step=0.1, value=1.2)
top_p = gr.Slider(0.0, 1.0, label="Top P", step=0.05, value=0.5)
presence_penalty = gr.Slider(0.0, 1.0, label="Presence Penalty", step=0.1, value=0.4)
count_penalty = gr.Slider(0.0, 1.0, label="Count Penalty", step=0.1, value=0.4)
앱 실행
이제 python app.py 를 실행한다.
(venv)$ python app.py
맨 마지막에 표시되는 http://127.0.0.1:7860 을 브라우저로 접속하면 이제 2000토큰짜리 나만의 ChatGPT가 탄생한다.
Bug?
토큰 수를 억지로 열 배로 올린 탓에 생성이 썩 매끄럽지는 못하다. 예를 들어 꽤 복잡한 알고리즘인 B+ Tree알고리즘을 써달라고 하면 열심히 쓰다가 중간에 애가 맛이 가는 것을 확인할 수 있다.
write me a b+ tree algorithm in c
사용 후기
그리고 코딩 외의 질문은 내가 잘 할 줄 몰라서 그냥 두었다. 사실 그냥 일상적인 질문은 Bing Chat 에서 하면 된다(엣지 브라우저가 필수라는 점은 좀 아플 수도 있겠다. 리눅스 사용자는?)
코딩 중에 자잘하면서도 유용한 도움을 주는 건 깃허브 코파일럿 이 더 낫다. 주석으로 뭘 원하는지 쓰면 알아서 코드를 밑에 박아주니까. 마음에 안 들면 Ctrl+Enter 눌러서 다른 제안을 볼 수도 있다. 주석으로 설명하는 정도에서 끝나는 것도 아니라 뭔가 단순반복작업 같은 걸 하고 있으면 코파일럿이 알아서 나머지 내용을 다 적어주기 때문에 난 그냥 tab만 누르면 된다.
마지막으로, 얘는 연속된 질문을 하기가 어렵다. input 창 안에다가 컨텍스트를 주면 어떻게든 비슷하게 흉내낼 수 있지만 역시 대화형 코드 생성(?)은 ChatGPT가 제일 낫다.
그래도 일할 때 인터넷을 틀어막아버리는(소문만 들었다) 금융권 개발자들에게는 이런 게 필요하지 않을까 생각해본다. 어째서 데이터베이스 로직 짜는데 RTX4090 이 필요한지 설득하는 일은 여러분에게 맡긴다 😁😁😁
번외: 구글 코랩?
구글 코랩에서도 돌릴 수 있다.
새 노트북 생성
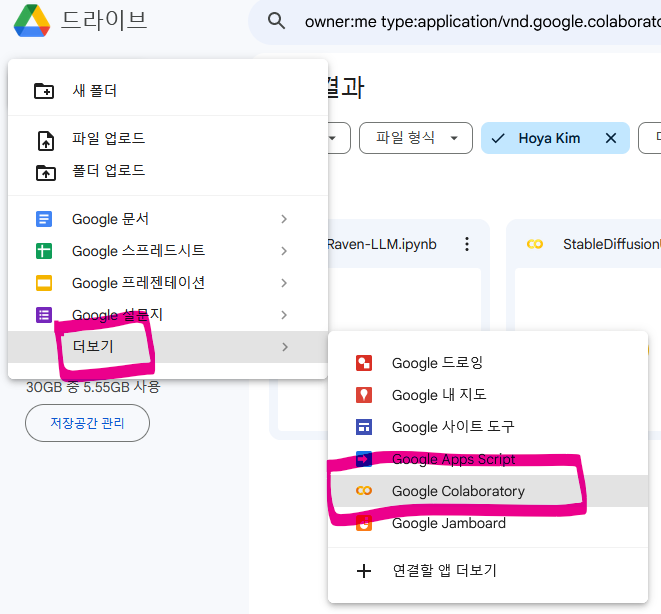
app.py 이식
app.py 코드를 코랩 노트북에 복사하고 위에 코드 블럭을 하나 추가한 뒤 requirements.txt 파일의 내용을 노트북 상단에 pip 설치 명령만 추가해준다.
!pip install torch ninja tokenizers rwkv==0.6.2 pynvml huggingface_hub "gradio>=3.17.1"
20B_tokenizer.json 복사
코랩의 파일 탭을 열어 20B_tokenizer.json 을 업로드한다. 드래그 드롭하면 된다.
이 파일은 세션이 종료되면 자동으로 삭제되므로 코랩을 켤 때마다 이 작업을 반복해줘야 한다. 귀찮으면 구글 드라이브 연결해서 거기 올려두세요.
파라미터 튜닝
하지만 이것만 하면 왠지 시스템 메모리를 과하게 쓰다가 런타임이 다운된다. 허깅페이스보다 리소스를 짜게 주는 게 확실한 것 같다. 그런데 리소스 사용량을 보면 GPU 메모리는 런타임이 뻗을 때까지도 상당히 여유가 있는 모습을 보였다.
기본 모델도 메모리를 크게 차지하므로 다운받을 모델 파일을 수정한다. title 변수를 찾아 아래와 같이 바꿔준다.
title = "RWKV-4-Raven-3B-v9-Eng99%-Other1%-20230411-ctx4096"
strategy를 수정한다.
원래 코드에 있는 model = RWKV( ... )부분을 아래와 같이 수정한다.
model = RWKV(model=model_path, strategy='cuda fp16')
다음, 코드 맨 아래 gradio 부분도 수정한다. demo.launch(share=False) 를 demo.launch(share=True) 으로 수정한다.
demo.launch(share=True)
마지막으로 우리는 데모보다 더 많은 토큰 수를 원하므로, token 수를 2000 개로 조정한다. 아래 세 부분을 바꾸면 된다.
def evaluate(
instruction,
input=None,
##############################
token_count=2000, # 200 → 2000
##############################
temperature=1.0,
top_p=0.7,
presencePenalty = 0.1,
countPenalty = 0.1,
):
with gr.Column():
instruction = gr.Textbox(lines=2, label="Instruction", value="Tell me about ravens.")
input = gr.Textbox(lines=2, label="Input", placeholder="none")
###########################################
# Edit this below. 200 -> 2000, value=150 -> 2000
token_count = gr.Slider(10, 2000, label="Max Tokens", step=10, value=2000)
###########################################
temperature = gr.Slider(0.2, 2.0, label="Temperature", step=0.1, value=1.2)
top_p = gr.Slider(0.0, 1.0, label="Top P", step=0.05, value=0.5)
presence_penalty = gr.Slider(0.0, 1.0, label="Presence Penalty", step=0.1, value=0.4)
count_penalty = gr.Slider(0.0, 1.0, label="Count Penalty", step=0.1, value=0.4)
이제 Ctrl+F9 눌러서 전체 셀을 실행한다. 런타임이 다운될 수도 있는데 자동으로 재접속하므로 다시 Ctrl+F9 누르면 어쩌면… 작동한다. 시스템 RAM을 거의 다 사용하기 때문에 어쩔 수가 없다.
실행 후, Running on public URL: https://e1fe7ba66d19932684.gradio.live 과 같은 줄을 찾아 클릭하면 된다.
댓글남기기